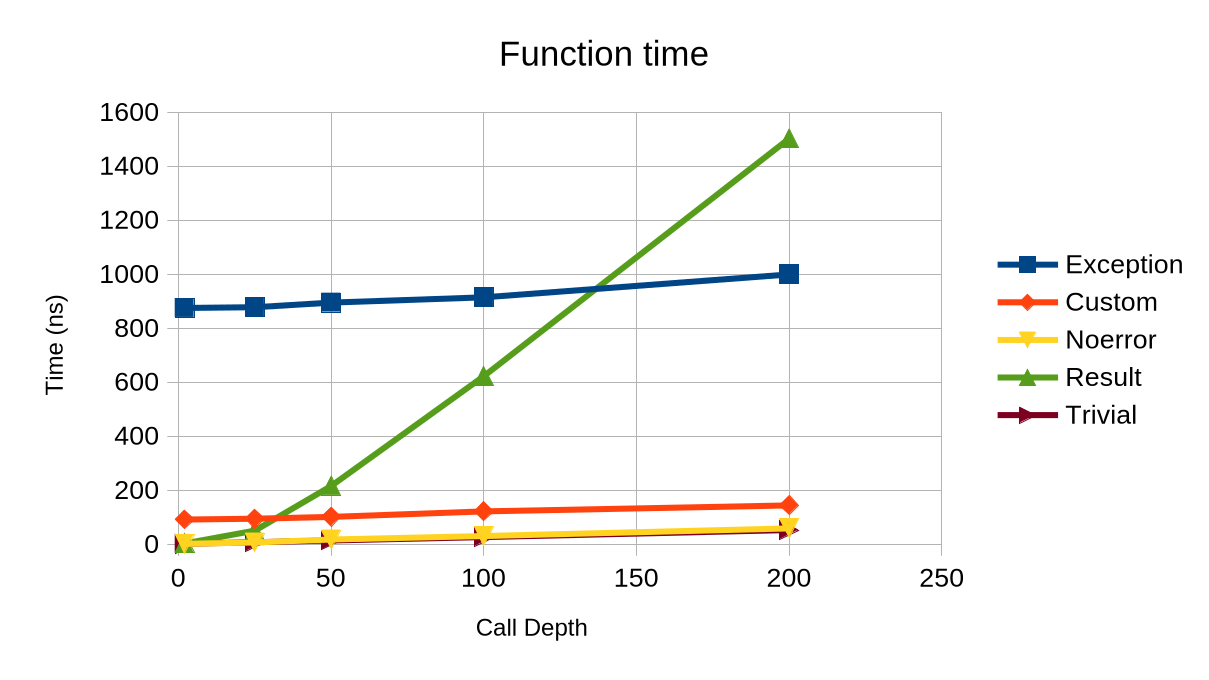
I’ve written a new unwinding runtime for GCC, and benchmarked it against various error handling regimes. It’s incredibly fast, 10x faster than the current implementation on x86 linux, but still slower than a normal function call (3x slower) and sometimes faster than return-type error handling.
Benchmark code: https://github.com/DolphinGui/eh-bench
GCC branch with patches: https://github.com/DolphinGui/gcc/tree/x86-exceptions-fr
binutils branch with patches: https://github.com/DolphinGui/binutils/tree/x86-exceptions
Background
Modern error handling in C++ generally falls under two methods:
return type error handling and exceptions. Return type error handling
(which shall be referred to as Result-based) is when the function
returns a variant of either the error or the result. This is commonly
done via std::optional or std::expected. Exception-based error
handling is when the error is indicated by throwing an exception,
usually a superclass of std::exception, which is then caught
up the call stack.
The ergonomics and performance implications of exceptions and Result-types have been much the subject of debate in C++. This article does not discuss the ergonomics of either, but instead focuses on how the performance of exceptions can be improved.
Methodology
struct Result{
bool is_some;
int result;
~Result();
};
struct Trivial{
bool is_some;
int result;
};
struct ExceptionBase {};
struct ExceptionA : ExceptionBase {
ExceptionA(int t) : type(t) {}
int type;
};
// Defined in some cpp file
Result::~Result = default;
// defined separately to prevent inlining
The results were tested on a Intel i5-1135G7 laptop. The benchmark used
Google Benchmark, testing only error handling with the above error types.
Said error types were intentionally simplified to remove the influence of
the cost of the error type itself from the benchmark. The reason why
Result and Trivial are two seperate types are to seperate the case where
the result type has a trivial destructor versus where it doesn’t.
I generated a callstack of 200 different functions with varying amounts of parameters. Exception unwinding functions used the same functions as the noerror case, whereas the Trivial and Result functions required separate functions. This was done in contrast to prior work, which typically used the fibonacci function or some other recursive function as their load. However, a recursive function is more likely to be in i-cache than functions calling eachother, which may advantage result types over exception handling.
Performance Breakdown
 Unsurprisingly, exception handling has a large constant cost, which represents
a combination of the complex exception runtime as well as the cost
of the unwinder itself. In comparison, both the trivial and non-trivial result-based
error handling start out with about the same amount of cost. As call
depth increases however, the null case (noerror) and trivial become cheaper
while nontrivial result types become significantly more expensive.
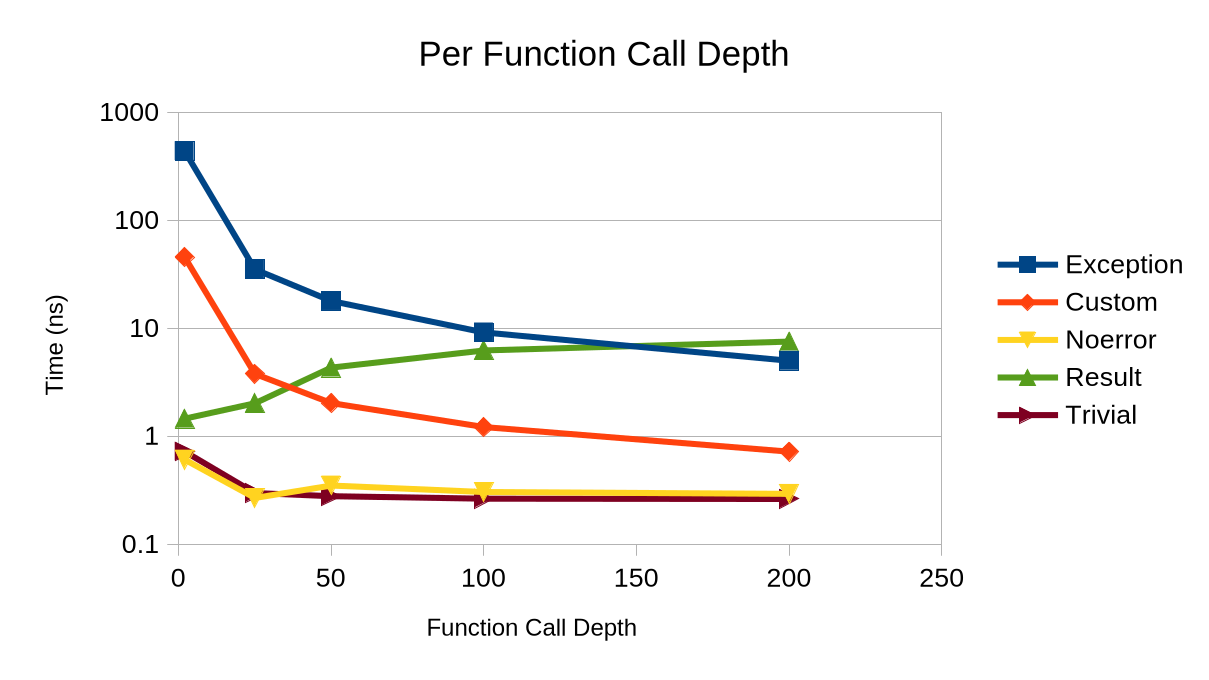
Unsurprisingly, exception handling has a large constant cost, which represents
a combination of the complex exception runtime as well as the cost
of the unwinder itself. In comparison, both the trivial and non-trivial result-based
error handling start out with about the same amount of cost. As call
depth increases however, the null case (noerror) and trivial become cheaper
while nontrivial result types become significantly more expensive.
In the end however, the branch predictor was still too strong. Trivial result types are nearly identical to normal functions, despite the addition of an additional branch. The non-trivial result type however saw a significantly higher per-function cost, which is probably because the Result type had be passed via stack due to the destructor.
Custom Exception Runtime
You may have spotted the “Custom” exception runtime, which seems to be an order of magnitude faster than the current exception runtime. The custom exception runtime is a patched version of GCC which uses a highly optimized exception runtime. This runtime removes much of the cruft of the old exception runtime, removing much of the business logic and speeding up function unwinding.
Mechanism
My exception runtime takes advantage of two trends in modern computer architecture: register generality and fixed function call conventions. By taking advantage of these two trends, it is possible to compress the information of a function stack significantly from a large amount of linear data to two integers.
Register generality
In modern computer architecutre, registers are generally thought of as general purpose varibles. This may seem somewhat obvious, but is actually a radical depature from older ISAs that have many special purpose registers.
Beating the dead horse of x86, x86’s mul instruction only works with
RAX and RDX. Similarly, on the 8-bit AVR architecture, the X and Y register pairs
are special addressing registers used by certain load operations.
This is not the case with modern architectures such as ARM and RISC-V, or even
POWER-PC and MIPS. The reason why this is very limiting should be obvious,
as it constrains the compiler from using whatever register for variables.
Because of this generality, modern compilers do not generally differentiate
significantly between registers. RAX is a register just as RBX is, and
the compiler is indifferent to which register it will use first. An important
consequence of this is that compilers will always allocate registers in a set order,
since there’s no reason not to.
Fixed function call conventions
Almost all modern software in the modern era uses functions. Moreover, it uses functions with a fixed set of conventions for pushing registers to stack, and how to allocate said stack. This may seem rather obvious and elementary to most, but this constraint is very important for function unwinding.
One consequence is that register allocation between functions is largely fixed. Functions that use too many registers must save certain registers, even if the called functions wouldn’t ever use those registers. Notably, it means that for a given function, there is a fixed structure that determines it’s stack layout. On x86, a function first must push any saved registers it uses. Then it must allocate any stack it uses.
Fast Exceptions
To recap, registers in a function are always in a set location in a function, and always appear in a certain order. This means that the stack frame of a function can always be summarized with two numbers: the number of registers used, and how much stack space was used. This is important because the primary task of exception handling is function unwinding. Encoding the function state in two numbers dramatically reduces the size and time required to unwind a function.
Register Unwinding
__gnu_fae_unwinder_x86_64v0:
leaq (%rdi,%rdi,4), %rax /* Multiply by -5, the size of a movq instruction */
negq %rax
addq $.unwind_start, %rax
jmp *%rax
movq 40(%rsp), %r15
movq 32(%rsp), %r14
movq 24(%rsp), %r13
movq 16(%rsp), %r12
movq 8(%rsp), %rbp
movq (%rsp), %rbx
nop /* Padding */
.unwind_start:
leaq 0(,%rdi,8), %rax /* Multiply number of registers by 8 bytes */
addq %rax, %rsp
jmp __fae_finish_unwinding
This is the implementation for the register unwinder on x86. It’s a normal “function”
that unwinds RDI number of registers. It uses a negatively indexed duff device
to load the registers from stack memory. After that, it adjusts the stack by
multiplying the number of registers, and restoring the stack used by said
number of registers.
This is, to my knowledge, the fastest way to unwind a stack frame. The only comparable is some research done by Bastian et al. where they transpiled DWARF tables to x86 instructions. Their approach has the benefit of taking advantage of the current DWARF runtime, but unfortunately seems to not have gone anywhere in terms of adoption. In any case, their implementation also takes more space than mine, which uses a single routine for all stack frames vs. a specific routine for each function.
Caveats
Unfortunately, there are several limitations with the current implementation. First, this assumes the function frame does not change in the middle of the function. This is a mostly reasonable assumption, as most unwinders (ARM, Windows) also assume this.
Unfortunately, it’s also not a universally true assumption. In the case of x86 on linux, it is possible for GCC to generate function calls that push arguments on top of the stack in the middle of stack. ARM GCC constrains code generation to pre-allocating registers before memory calling functions, but this isn’t true on x86. Because of that, my implementation does not work correctly with memory calls.
Also, my current implementation of unwind tables doesn’t correctly deal with shared libraries. I’m honestly not sure how shared library sections are placed anyways, but there’s no reason why it couldn’t work. I’d also like to switch from a sorted array to a b-tree for the exception table to improve lookup speed more. It would also be prudent to add support for DWARF for backwards compatability.